Publications
publications by categories in reversed chronological order.
2026
-
 VibeToken: Scaling 1D Image Tokenizers and Autoregressive Models for Dynamic Resolution GenerationsMaitreya Patel , Jingtao Li, Weiming Zhuang, Yezhou Yang, and Lingjuan Lv
VibeToken: Scaling 1D Image Tokenizers and Autoregressive Models for Dynamic Resolution GenerationsMaitreya Patel , Jingtao Li, Weiming Zhuang, Yezhou Yang, and Lingjuan Lv
In CVPR 2026@inproceedings{patel2026vibetoken, title = {VibeToken: Scaling 1D Image Tokenizers and Autoregressive Models for Dynamic Resolution Generations}, author = {Patel, Maitreya and Li, Jingtao and Zhuang, Weiming and Yang, Yezhou and Lv, Lingjuan}, booktitle = {CVPR}, year = {2026}, }
-
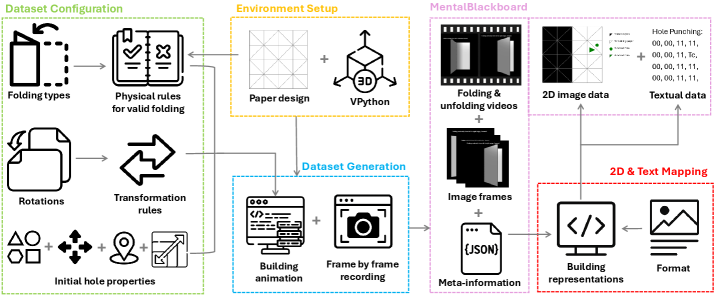 MentalBlackboard: Evaluating Spatial Visualization via Mathematical TransformationsNilay Yilmaz, Maitreya Patel , Naga Sai Abhiram Kusumba, Yiran He, and Yezhou Yang
MentalBlackboard: Evaluating Spatial Visualization via Mathematical TransformationsNilay Yilmaz, Maitreya Patel , Naga Sai Abhiram Kusumba, Yiran He, and Yezhou Yang
2026@article{yilmaz2026mentalblackboard, title = {MentalBlackboard: Evaluating Spatial Visualization via Mathematical Transformations}, author = {Yilmaz, Nilay and Patel, Maitreya and Kusumba, Naga Sai Abhiram and He, Yiran and Yang, Yezhou}, booktitle = {arXiv preprint}, year = {2026}, }
2025
-
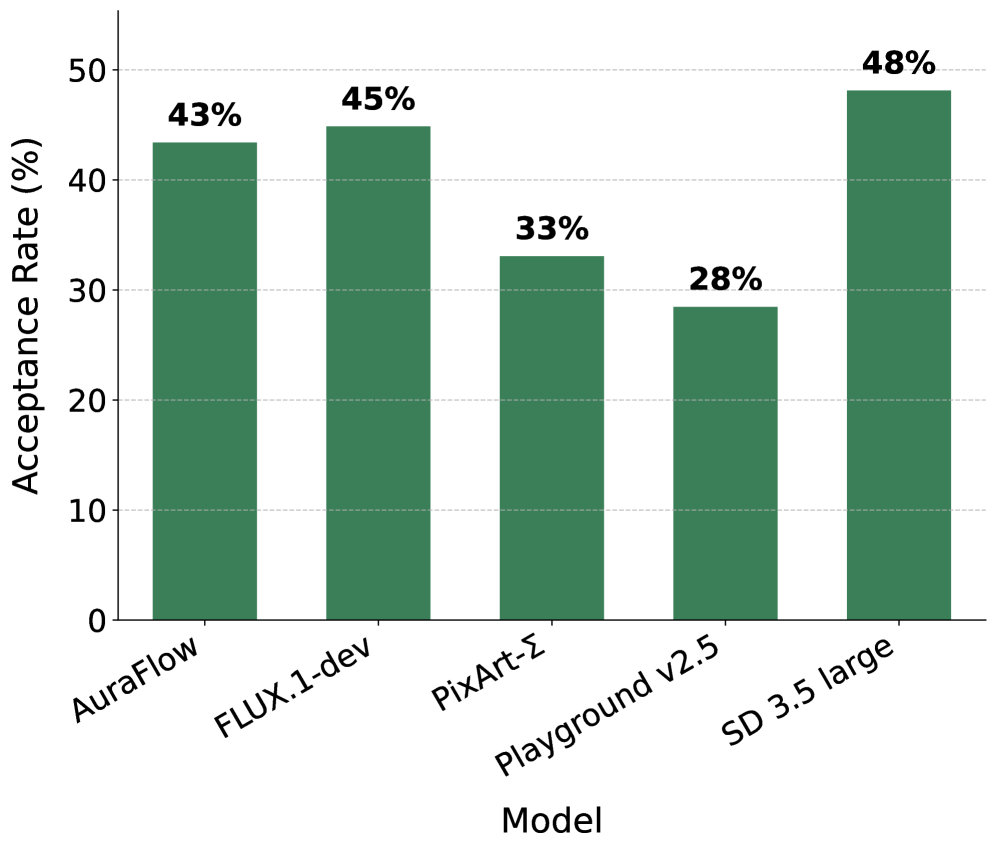 AcT2I: Evaluating and Improving Action Depiction in Text-to-Image ModelsVatsal Malaviya, Agneet Chatterjee, Maitreya Patel , Yezhou Yang, and Chitta Baral
AcT2I: Evaluating and Improving Action Depiction in Text-to-Image ModelsVatsal Malaviya, Agneet Chatterjee, Maitreya Patel , Yezhou Yang, and Chitta Baral
In EMNLP 2025@inproceedings{malaviya2025act2i, title = {AcT2I: Evaluating and Improving Action Depiction in Text-to-Image Models}, author = {Malaviya, Vatsal and Chatterjee, Agneet and Patel, Maitreya and Yang, Yezhou and Baral, Chitta}, booktitle = {EMNLP}, year = {2025}, }
-
 TextInVision: Text and Prompt Complexity Driven Visual Text Generation BenchmarkForouzan Fallah, Maitreya Patel , Agneet Chatterjee, Vlad I. Morariu, Chitta Baral, and Yezhou Yang
TextInVision: Text and Prompt Complexity Driven Visual Text Generation BenchmarkForouzan Fallah, Maitreya Patel , Agneet Chatterjee, Vlad I. Morariu, Chitta Baral, and Yezhou Yang
In CVPR Workshops 2025@inproceedings{fallah2025textinvision, title = {TextInVision: Text and Prompt Complexity Driven Visual Text Generation Benchmark}, author = {Fallah, Forouzan and Patel, Maitreya and Chatterjee, Agneet and Morariu, Vlad I. and Baral, Chitta and Yang, Yezhou}, booktitle = {CVPR Workshops}, year = {2025}, }
-
 EraseFlow: Learning Concept Erasure Policies via GFlowNet-Driven Alignment
EraseFlow: Learning Concept Erasure Policies via GFlowNet-Driven Alignment
In NeurIPS (Spotlight) 2025Erasing harmful or proprietary concepts from powerful text to image generators is an emerging safety requirement, yet current "concept erasure" techniques either collapse image quality, rely on brittle adversarial losses, or demand prohibitive retraining cycles. We trace these limitations to a myopic view of the denoising trajectories that govern diffusion based generation. We introduce EraseFlow, the first framework that casts concept unlearning as exploration in the space of denoising paths and optimizes it with GFlowNets equipped with the trajectory balance objective. By sampling entire trajectories rather than single end states, EraseFlow learns a stochastic policy that steers generation away from target concepts while preserving the model’s prior. EraseFlow eliminates the need for carefully crafted reward models and by doing this, it generalizes effectively to unseen concepts and avoids hackable rewards while improving the performance. Extensive empirical results demonstrate that EraseFlow outperforms existing baselines and achieves an optimal trade off between performance and prior preservation.
@inproceedings{pathiraja2025eraseflow, title = {EraseFlow: Learning Concept Erasure Policies via GFlowNet-Driven Alignment}, author = {Kusumba *, Abhiram and Patel *, Maitreya and Min, Kyle and Kim, Changhoon and Baral, Chitta and Yang, Yezhou}, booktitle = {NeurIPS (Spotlight)}, year = {2025}, url = {https://eraseflow.github.io/}, demo = {https://huggingface.co/EraseFlow}, }
-
 RefEdit: A Benchmark and Method for Improving Instruction-based Image Editing Model for Referring ExpressionBimsara Pathiraja *, Maitreya Patel *, Shivam Singh, Yezhou Yang, and Chitta Baral
RefEdit: A Benchmark and Method for Improving Instruction-based Image Editing Model for Referring ExpressionBimsara Pathiraja *, Maitreya Patel *, Shivam Singh, Yezhou Yang, and Chitta Baral
In ICCV 2025Diffusion models (DMs) excel in photorealism, image editing, and solving inverse problems, aided by classifier-free guidance and image inversion techniques. However, rectified flow models (RFMs) remain underexplored for these tasks. Existing DM-based methods often require additional training, lack generalization to pretrained latent models, underperform, and demand significant computational resources due to extensive backpropagation through ODE solvers and inversion processes. In this work, we first develop a theoretical and empirical understanding of the vector field dynamics of RFMs in efficiently guiding the denoising trajectory. Our findings reveal that we can navigate the vector field in a deterministic and gradient-free manner. Utilizing this property, we propose FlowChef, which leverages the vector field to steer the denoising trajectory for controlled image generation tasks, facilitated by gradient skipping. FlowChef is a unified framework for controlled image generation that, for the first time, simultaneously addresses classifier guidance, linear inverse problems, and image editing without the need for extra training, inversion, or intensive backpropagation. Finally, we perform extensive evaluations and show that FlowChef significantly outperforms baselines in terms of performance, memory, and time requirements, achieving new state-of-the-art results.
@inproceedings{pathiraja2025refedit, title = {RefEdit: A Benchmark and Method for Improving Instruction-based Image Editing Model for Referring Expression}, author = {Pathiraja *, Bimsara and Patel *, Maitreya and Singh, Shivam and Yang, Yezhou and Baral, Chitta}, booktitle = {ICCV}, year = {2025}, url = {https://refedit.vercel.app/}, demo = {https://huggingface.co/spaces/FlowChef/RefEdit-SD3}, }
-
 Steering Rectified Flow Models in the Vector Field for Controlled Image GenerationMaitreya Patel , Song Wen, Dimitris N. Metaxas, and Yezhou Yang
Steering Rectified Flow Models in the Vector Field for Controlled Image GenerationMaitreya Patel , Song Wen, Dimitris N. Metaxas, and Yezhou Yang
In ICCV 2025Diffusion models (DMs) excel in photorealism, image editing, and solving inverse problems, aided by classifier-free guidance and image inversion techniques. However, rectified flow models (RFMs) remain underexplored for these tasks. Existing DM-based methods often require additional training, lack generalization to pretrained latent models, underperform, and demand significant computational resources due to extensive backpropagation through ODE solvers and inversion processes. In this work, we first develop a theoretical and empirical understanding of the vector field dynamics of RFMs in efficiently guiding the denoising trajectory. Our findings reveal that we can navigate the vector field in a deterministic and gradient-free manner. Utilizing this property, we propose FlowChef, which leverages the vector field to steer the denoising trajectory for controlled image generation tasks, facilitated by gradient skipping. FlowChef is a unified framework for controlled image generation that, for the first time, simultaneously addresses classifier guidance, linear inverse problems, and image editing without the need for extra training, inversion, or intensive backpropagation. Finally, we perform extensive evaluations and show that FlowChef significantly outperforms baselines in terms of performance, memory, and time requirements, achieving new state-of-the-art results.
@inproceedings{patel2024flowchef, title = {Steering Rectified Flow Models in the Vector Field for Controlled Image Generation}, author = {Patel, Maitreya and Wen, Song and Metaxas, Dimitris N. and Yang, Yezhou}, booktitle = {ICCV}, year = {2025}, url = {https://flowchef.github.io/}, demo = {https://huggingface.co/spaces/FlowChef/FlowChef-Flux1-dev}, }
-
 Voilà: Evaluation of MLLMs For Perceptual Understanding and Analogical ReasoningNilay Yilmaz, Maitreya Patel , Yiran Luo, Tejas Gokhale, Chitta Baral, Suren Jayasuriya, and 1 more author
Voilà: Evaluation of MLLMs For Perceptual Understanding and Analogical ReasoningNilay Yilmaz, Maitreya Patel , Yiran Luo, Tejas Gokhale, Chitta Baral, Suren Jayasuriya, and 1 more author
In ICLR (Main Conference) – 2025Multimodal Large Language Models (MLLMs) have become a powerful tool for integrating visual and textual information. Despite their exceptional performance on visual understanding benchmarks, measuring their ability to reason abstractly across multiple images remains a significant challenge. To address this, we introduce VOILA , a large-scale, open-ended, dynamic benchmark designed to evaluate MLLMs’ perceptual understanding and abstract relational reasoning. VOILA employs an analogical mapping approach in the visual domain, requiring models to generate an image that completes an analogy between two given image pairs, reference and application, without relying on predefined choices. Our experiments demonstrate that VOILA presents MLLMs with demanding relational reasoning tasks. Through multi-step analysis, we reveal that current MLLMs struggle to comprehend inter-image relationships and exhibit limited capabilities in highlevel relational reasoning. Notably, we observe that performance improves when using least-to-most prompting strategies. Comprehensive evaluations on opensource models and GPT-4o show that while the MolmoE-8B model achieves a state-of-the-art performance of 34% and 19% at finding the text-based answer to the questions on easy and hard scenarios, human performance consistently remains significantly higher at 70% on both difficulty scenarios.
@inproceedings{yilmaz2025voila, title = {Voilà: Evaluation of MLLMs For Perceptual Understanding and Analogical Reasoning}, author = {Yilmaz, Nilay and Patel, Maitreya and Luo, Yiran and Gokhale, Tejas and Baral, Chitta and Jayasuriya, Suren and Yang, Yezhou}, booktitle = {ICLR (Main Conference) --}, year = {2025}, }
2024
-
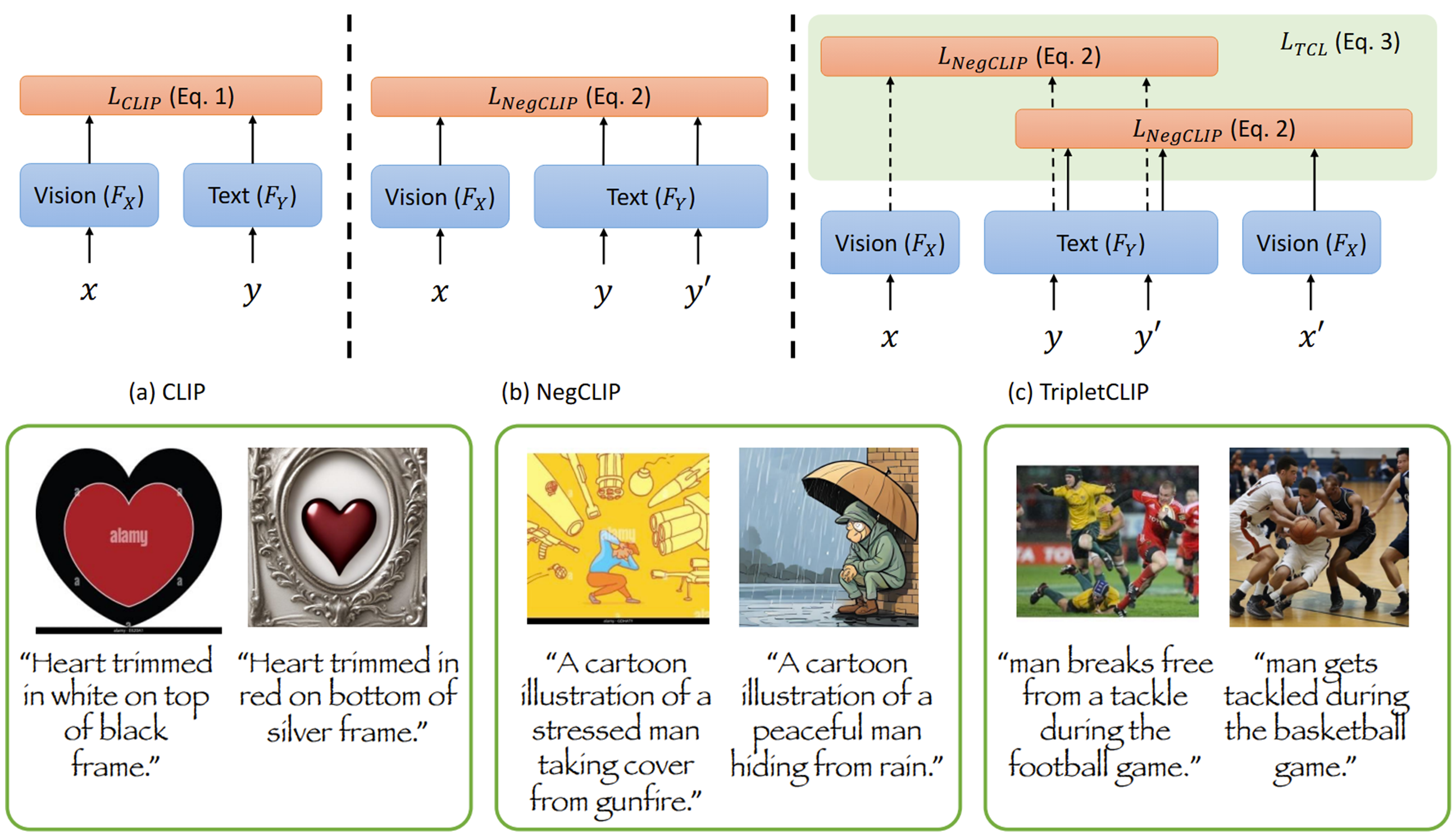 TripletCLIP: Improving Compositional Reasoning of CLIP via Vision-Language Negatives
TripletCLIP: Improving Compositional Reasoning of CLIP via Vision-Language Negatives
In NeurIPS (Main Conference) – 2024Contrastive Language-Image Pretraining (CLIP) models maximize the mutual information between text and visual modalities to learn representations. This makes the nature of the training data a significant factor in the efficacy of CLIP for downstream tasks. However, the lack of compositional diversity in contemporary image-text datasets limits the compositional reasoning ability of CLIP. We show that generating “hard” negative captions via in-context learning and synthesizing corresponding negative images with text-to-image generators offers a solution. We introduce a novel contrastive pre-training strategy that leverages these hard negative captions and images in an alternating fashion to train CLIP. We demonstrate that our method, named TripletCLIP, when applied to existing datasets such as CC3M and CC12M, enhances the compositional capabilities of CLIP, resulting in an absolute improvement of over 9% on the SugarCrepe benchmark on an equal computational budget, as well as improvements in zero-shot image classification and image retrieval. Our negative data generation strategy, data, and code will be open-sourced.
@inproceedings{patel2024tripletclip, title = {TripletCLIP: Improving Compositional Reasoning of CLIP via Vision-Language Negatives}, author = {Patel, Maitreya and Kusumba, Abhiram and Cheng, Sheng and Kim, Changhoon and Baral, Chitta and Yang, Yezhou}, booktitle = {NeurIPS (Main Conference) -- }, year = {2024}, url = {https://tripletclip.github.io/}, data = {https://huggingface.co/TripletCLIP/} }
-
 λ-ECLIPSE: Multi-Concept Personalized Text-to-Image Diffusion Models by Leveraging CLIP Latent SpaceMaitreya Patel , Sangmin Jung, Chitta Baral, and Yezhou YangMedia Coverages: AK , MarkTechPost
λ-ECLIPSE: Multi-Concept Personalized Text-to-Image Diffusion Models by Leveraging CLIP Latent SpaceMaitreya Patel , Sangmin Jung, Chitta Baral, and Yezhou YangMedia Coverages: AK , MarkTechPost
In Transactions on Machine Learning Research (TMLR) 2024Despite the recent advances in personalized text-to-image (P-T2I) generative models, it remains challenging to perform finetuning-free multi-subject-driven T2I in a resource-efficient manner. Predominantly, contemporary approaches, involving the training of Hypernetworks and Multimodal Large Language Models (MLLMs), require heavy computing resources that range from 600 to 12300 GPU hours of training. In this paper, we present λ-ECLIPSE, an alternative prior-training strategy that works in the latent space of a pre-trained CLIP model without relying on the diffusion UNet models. λ-ECLIPSE leverages the novel image-text interleaved pre-training for fast and effective multi-subject-driven P-T2I. Through extensive experiments, we establish that λ-ECLIPSE surpasses existing baselines in composition alignment while preserving concept alignment performance, even with significantly lower resource utilization. λ-ECLIPSE performs multi-subject driven P-T2I with just 34M parameters and is trained on a mere 74 GPU hours. Additionally, λ-ECLIPSE achieves better balance with Canny edge-controlled subject-driven generations and demonstrates the unique ability to perform multi-concept interpolations.
@inproceedings{patel2024lambda, title = {λ-ECLIPSE: Multi-Concept Personalized Text-to-Image Diffusion Models by Leveraging CLIP Latent Space}, author = {Patel, Maitreya and Jung, Sangmin and Baral, Chitta and Yang, Yezhou}, booktitle = {Transactions on Machine Learning Research (TMLR)}, year = {2024}, url = {https://eclipse-t2i.github.io/Lambda-ECLIPSE/}, demo = {https://huggingface.co/spaces/ECLIPSE-Community/lambda-eclipse-personalized-t2i}, media1 = {https://x.com/_akhaliq/status/1755798954476806422?s=20}, media2 = {https://www.marktechpost.com/2024/02/23/arizona-state-university-researchers-%CE%BB-eclipse-a-novel-diffusion-free-methodology-for-personalized-text-to-image-t2i-applications/} }
-
 Precision or Recall? An Analysis of Image Captions for Training Text-to-Image Generation ModelSheng Cheng, Maitreya Patel , and Yezhou Yang
Precision or Recall? An Analysis of Image Captions for Training Text-to-Image Generation ModelSheng Cheng, Maitreya Patel , and Yezhou Yang
In EMNLP (findings) – 2024Recent text-to-image models often struggle to generate images that accurately align with given text, due to misalignments between training image and text pairs. In this paper, we analyze the critical role of caption precision and recall in text-to-image model training. Our analysis of human-annotated captions shows that both precision and recall are important for text-image alignment, but precision has a more significant impact. Leveraging these insights, we utilize Large Vision Language Models to generate synthetic captions for training. The performance of these models, closely mirroring that of models trained using human-annotated captions, underscores insights for the future use of synthetic data in text-to-image training.
@inproceedings{cheng2024precision, title = {Precision or Recall? An Analysis of Image Captions for Training Text-to-Image Generation Model}, author = {Cheng, Sheng and Patel, Maitreya and Yang, Yezhou}, booktitle = {EMNLP (findings) -- }, year = {2024}, }
-
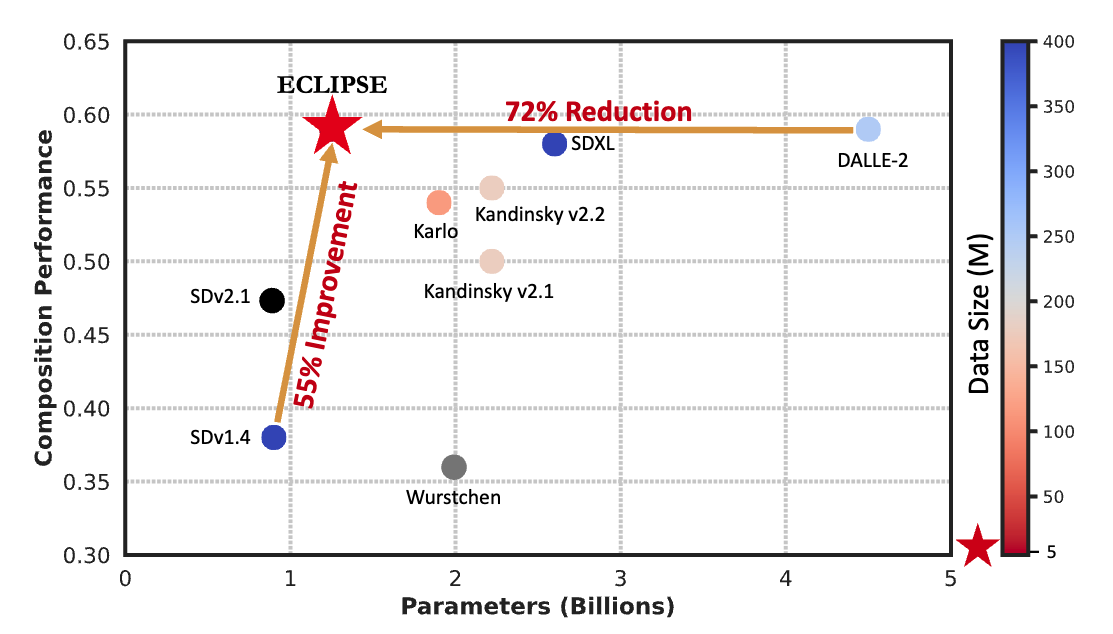 ECLIPSE:A Resource-Efficient Text-to-Image Prior for Image Generations
ECLIPSE:A Resource-Efficient Text-to-Image Prior for Image Generations
In CVPR – 2024Text-to-image (T2I) diffusion models, notably the unCLIP models (e.g., DALL-E-2), achieve state-of-the-art (SOTA) performance on various compositional T2I benchmarks, at the cost of significant computational resources. The unCLIP stack comprises T2I prior and diffusion image decoder. The T2I prior model alone adds a billion parameters compared to the Latent Diffusion Models, which increases the computational and high-quality data requirements. We introduce ECLIPSE, a novel contrastive learning method that is both parameter and data-efficient. ECLIPSE leverages pre-trained vision-language models (e.g., CLIP) to distill the knowledge into the prior model. We demonstrate that the ECLIPSE trained prior, with only 3.3% of the parameters and trained on a mere 2.8% of the data, surpasses the baseline T2I priors with an average of 71.6% preference score under resource-limited setting. It also attains performance on par with SOTA larger models, achieving an average of 63.36% preference score in terms of the ability to follow the text compositions. Extensive experiments on two unCLIP diffusion image decoders, Karlo and Kandinsky, affirm that ECLIPSE consistently delivers high performance while significantly reducing resource dependency.
@inproceedings{patel2024eclipse, title = {ECLIPSE:A Resource-Efficient Text-to-Image Prior for Image Generations}, author = {Patel, Maitreya and Kim, Changhoon and Cheng, Sheng and Baral, Chitta and Yang, Yezhou}, booktitle = {CVPR -- }, year = {2024}, url = {https://eclipse-t2i.vercel.app}, demo = {https://huggingface.co/spaces/ECLIPSE-Community/ECLIPSE-Kandinsky-v2.2}, media1 = {https://x.com/_akhaliq/status/1734036192817971630?s=61&t=IcCTFKB2lsUjjS6XkHQ9Tw}, media2 = {https://www.marktechpost.com/2023/12/13/this-ai-research-from-arizona-state-university-unveil-eclipse-a-novel-contrastive-learning-strategy-to-improve-the-text-to-image-non-diffusion-prior/}, media3 = {https://multiplatform.ai/eclipse-a-game-changer-in-text-to-image-generation-unveiled-by-arizona-state-university/}, media4 = {https://youtu.be/jjcMmIGottQ?si=DKqWE8lnOfjB-rx9} }
-
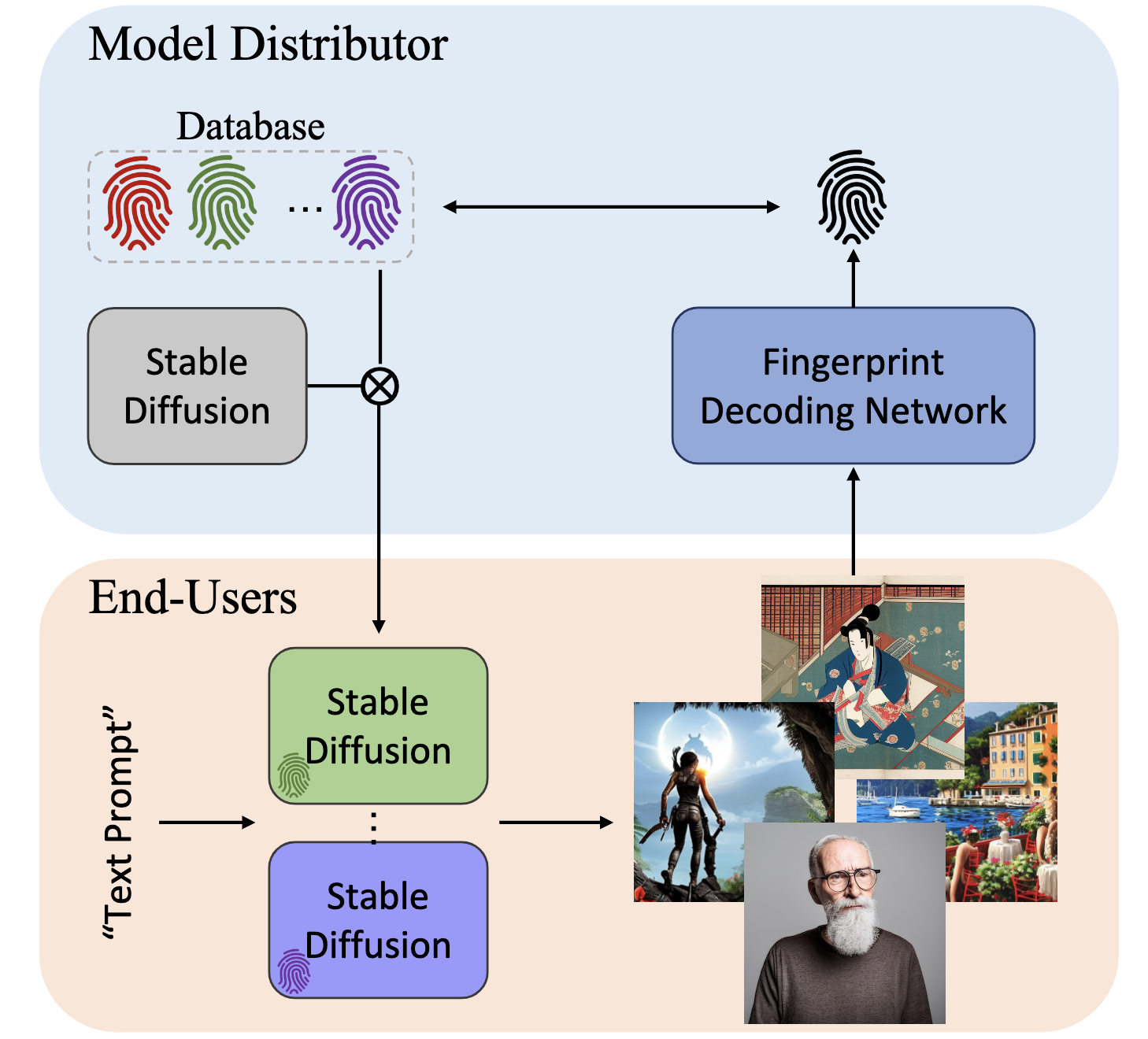 WOUAF: Weight Modulation for User Attribution and Fingerprinting in Text-to-Image Diffusion ModelsMedia Coverages: AK
WOUAF: Weight Modulation for User Attribution and Fingerprinting in Text-to-Image Diffusion ModelsMedia Coverages: AK
In CVPR – 2024The rapid advancement of generative models, facilitating the creation of hyper-realistic images from textual descriptions, has concurrently escalated critical societal concerns such as misinformation. Traditional fake detection mechanisms, although providing some mitigation, fall short in attributing responsibility for the malicious use of synthetic images. This paper introduces a novel approach to model fingerprinting that assigns responsibility for the generated images, thereby serving as a potential countermeasure to model misuse. Our method modifies generative models based on each user’s unique digital fingerprint, imprinting a unique identifier onto the resultant content that can be traced back to the user. This approach, incorporating fine-tuning into Text-to-Image (T2I) tasks using the Stable Diffusion Model, demonstrates near-perfect attribution accuracy with a minimal impact on output quality. We rigorously scrutinize our method’s secrecy under two distinct scenarios: one where a malicious user attempts to detect the fingerprint, and another where a user possesses a comprehensive understanding of our method. We also evaluate the robustness of our approach against various image post-processing manipulations typically executed by end-users. Through extensive evaluation of the Stable Diffusion models, our method presents a promising and novel avenue for accountable model distribution and responsible use.
@inproceedings{kim2024wouaf, title = {WOUAF: Weight Modulation for User Attribution and Fingerprinting in Text-to-Image Diffusion Models}, author = {Kim*, Changhoon and Min*, Kyle and Patel, Maitreya and Cheng, Sheng and Yang, Yezhou}, booktitle = {CVPR -- }, year = {2024}, url = {https://wouaf.vercel.app/}, demo = {https://huggingface.co/spaces/mpatel57/WOUAF-Text-to-Image}, media1 = {https://x.com/_akhaliq/status/1683678703048613888?s=46&t=XjL7XPmZ27Ev6ec3m2Wopw} }
2023
-
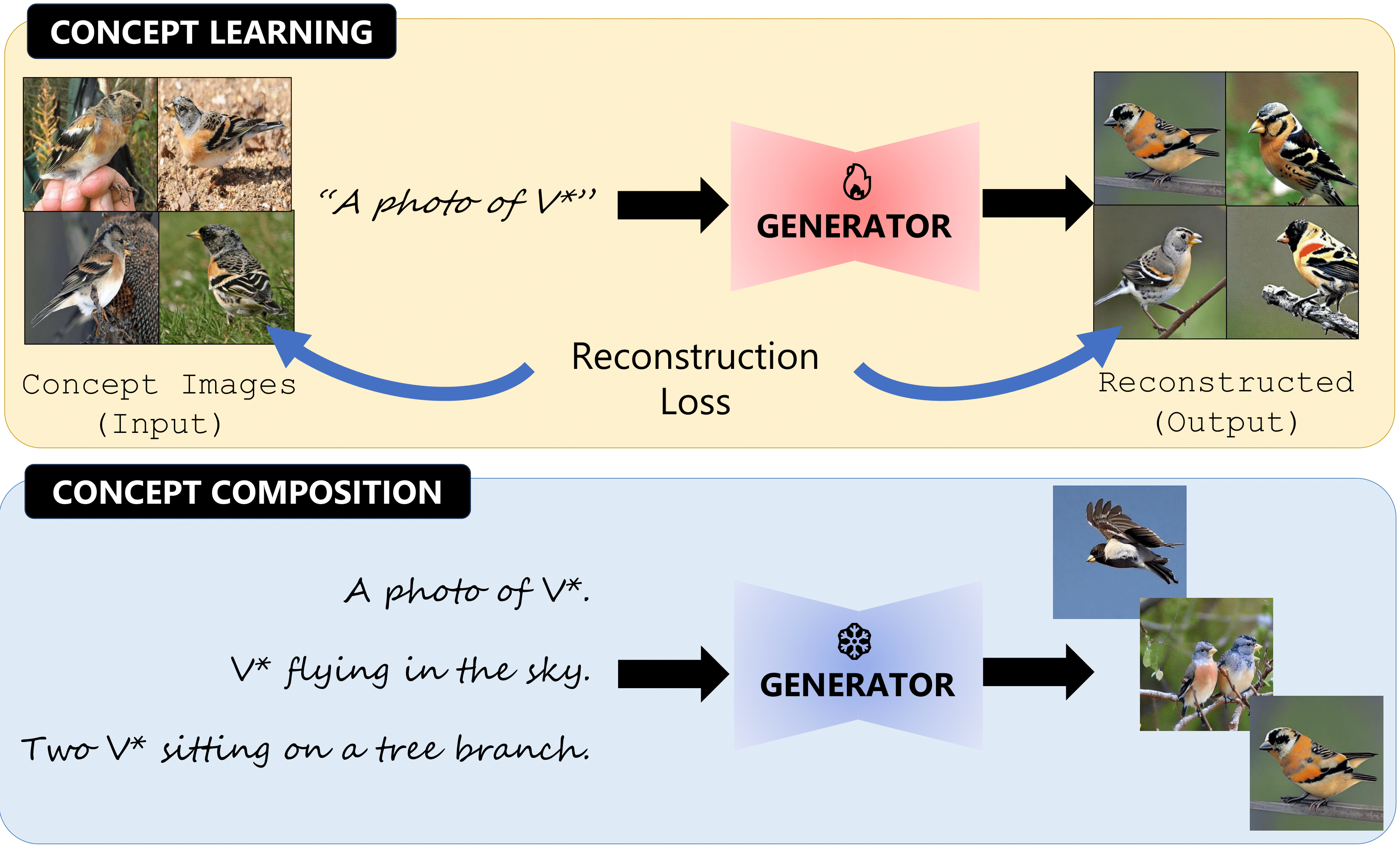 ConceptBed: Evaluating Concept Learning Abilities of Text-to-Image Diffusion Models
ConceptBed: Evaluating Concept Learning Abilities of Text-to-Image Diffusion Models
In AAAI’24 | Diffusion Workshop at NeurIPS – 2023The ability to understand visual concepts and replicate and compose these concepts from images is a central goal for computer vision. Recent advances in text-to-image (T2I) models have lead to high definition and realistic image quality generation by learning from large databases of images and their descriptions. However, the evaluation of T2I models has focused on photorealism and limited qualitative measures of visual understanding. To quantify the ability of T2I models in learning and synthesizing novel visual concepts, we introduce ConceptBed, a large-scale dataset that consists of 284 unique visual concepts, 5K unique concept compositions, and 33K composite text prompts. Along with the dataset, we propose an evaluation metric, Concept Confidence Deviation (CCD), that uses the confidence of oracle concept classifiers to measure the alignment between concepts generated by T2I generators and concepts contained in ground truth images. We evaluate visual concepts that are either objects, attributes, or styles, and also evaluate four dimensions of compositionality: counting, attributes, relations, and actions. Our human study shows that CCD is highly correlated with human understanding of concepts. Our results point to a trade-off between learning the concepts and preserving the compositionality which existing approaches struggle to overcome.
@inproceedings{patel2023conceptbed, title = {ConceptBed: Evaluating Concept Learning Abilities of Text-to-Image Diffusion Models}, author = {Patel, Maitreya and Gokhale, Tejas and Baral, Chitta and Yang, Yezhou}, booktitle = {AAAI'24 | Diffusion Workshop at NeurIPS -- }, year = {2023}, url = {https://conceptbed.github.io/}, demo = {https://huggingface.co/spaces/mpatel57/ConceptBed}, }
2022
-
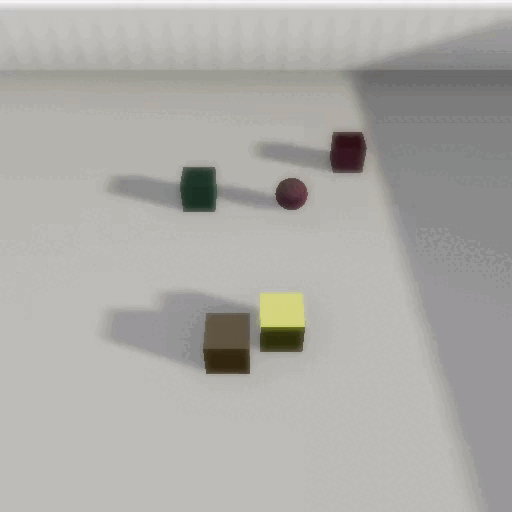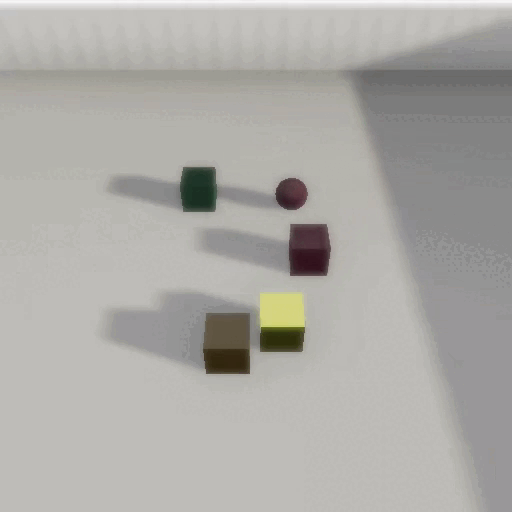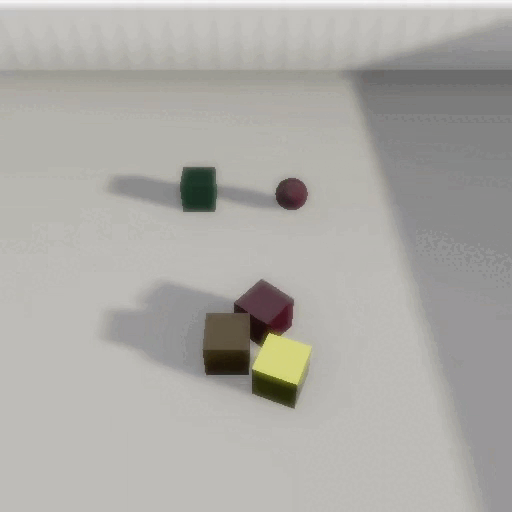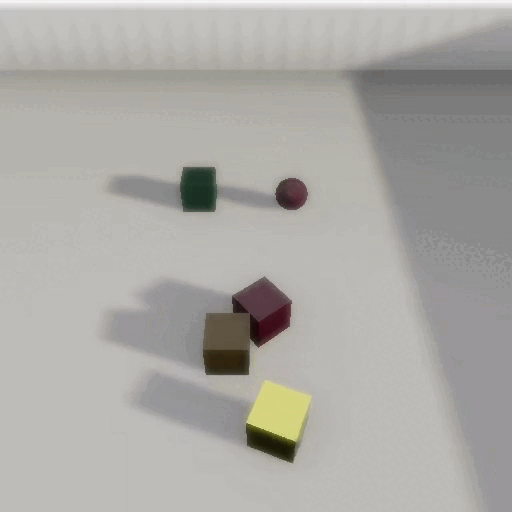 CRIPP-VQA: Counterfactual Reasoning about Implicit Physical Properties via Video Question Answering
CRIPP-VQA: Counterfactual Reasoning about Implicit Physical Properties via Video Question Answering
In EMNLP, Main Conference – 2022Videos often capture objects, their motion, and the interactions between different objects. Although real-world objects have physical properties associated with them, many of these properties (such as mass and coefficient of friction) are not captured directly by the imaging pipeline. However, these properties can be estimated by utilizing cues from relative object motion and the dynamics introduced by collisions. In this paper, we introduce a new video question answering task for reasoning about the implicit physical properties of objects in a scene, from videos. For this task, we introduce a dataset – CRIPP-VQA, which contains videos of objects in motion, annotated with hypothetical/counterfactual questions about the effect of actions (such as removing, adding, or replacing objects), questions about planning (choosing actions to perform in order to reach a particular goal), as well as descriptive questions about the visible properties of objects. We benchmark the performance of existing video question answering models on two test settings of CRIPP-VQA: \textiti.i.d. and an out-of-distribution setting which contains objects with values of mass, coefficient of friction, and initial velocities that are not seen in the training distribution. Our experiments reveal a surprising and significant performance gap in terms of answering questions about implicit properties (the focus of this paper) and explicit properties (the focus of prior work) of objects.
@inproceedings{patel2022cripp, title = {{CRIPP-VQA}: Counterfactual Reasoning about Implicit Physical Properties via Video Question Answering}, author = {Patel, Maitreya and Gokhale, Tejas and Baral, Chitta and Yang, Yezhou}, booktitle = {EMNLP, Main Conference -- }, year = {2022}, url = {https://maitreyapatel.com/CRIPP-VQA/}, }
-
 Benchmarking generalization via in-context instructions on 1,600+ language tasksYizhong Wang, Swaroop Mishra, Pegah Alipoormolabashi, Yeganeh Kordi, Amirreza Mirzaei, and others
Benchmarking generalization via in-context instructions on 1,600+ language tasksYizhong Wang, Swaroop Mishra, Pegah Alipoormolabashi, Yeganeh Kordi, Amirreza Mirzaei, and others
In EMNLP, Main Conference – 2022How can we measure the generalization of models to a variety of unseen tasks when provided with their language instructions? To facilitate progress in this goal, we introduce Natural-Instructions v2, a benchmark of 1,600+ diverse language tasks and their expert-written instructions. It covers 70+ distinct task types, such as tagging, in-filling, and rewriting. These tasks are collected with contributions of NLP practitioners in the community and through an iterative peer review process to ensure their quality. With this large and diverse collection of tasks, we are able to rigorously benchmark cross-task generalization of models – training on a subset of tasks and evaluating on the remaining unseen ones. For instance, we quantify generalization as a function of various scaling parameters, such as the number of observed tasks, the number of instances, and model sizes. Based on these insights, we introduce Tk-Instruct, an encoder-decoder Transformer that is trained to follow a variety of in-context instructions (plain language task definitions or k-shot examples) which outperforms existing larger models on our benchmark. We hope this benchmark facilitates future progress toward more general-purpose language understanding models.
@inproceedings{wang2022benchmarking, title = {Benchmarking generalization via in-context instructions on 1,600+ language tasks}, author = {Wang, Yizhong and Mishra, Swaroop and Alipoormolabashi, Pegah and Kordi, Yeganeh and Mirzaei, Amirreza and others}, booktitle = {EMNLP, Main Conference -- }, year = {2022}, url = {https://instructions.apps.allenai.org}, }
2020
-
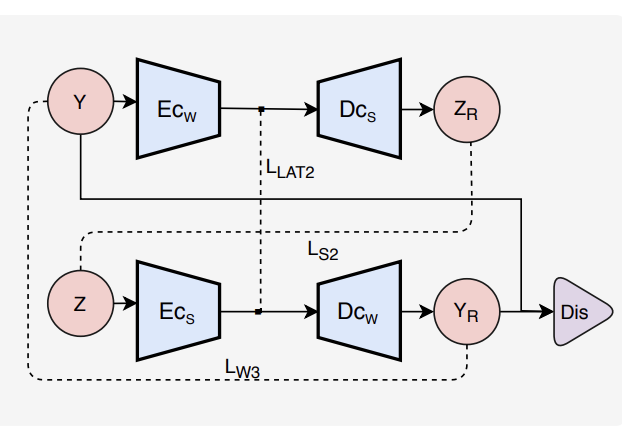 MSpeC-Net: Multi-Domain Speech Conversion NetworkHarshit Malaviya, Jui Shah, Maitreya Patel , Jalansh Munshi, and Hemant A Patil
MSpeC-Net: Multi-Domain Speech Conversion NetworkHarshit Malaviya, Jui Shah, Maitreya Patel , Jalansh Munshi, and Hemant A Patil
In 45th IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) 2020@inproceedings{malaviya2020mspec, title = {{MSpeC-Net}: Multi-Domain Speech Conversion Network}, author = {Malaviya, Harshit and Shah, Jui and Patel, Maitreya and Munshi, Jalansh and Patil, Hemant A}, booktitle = {45th IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)}, pages = {7764--7768}, year = {2020}, organization = {IEEE}, }
-
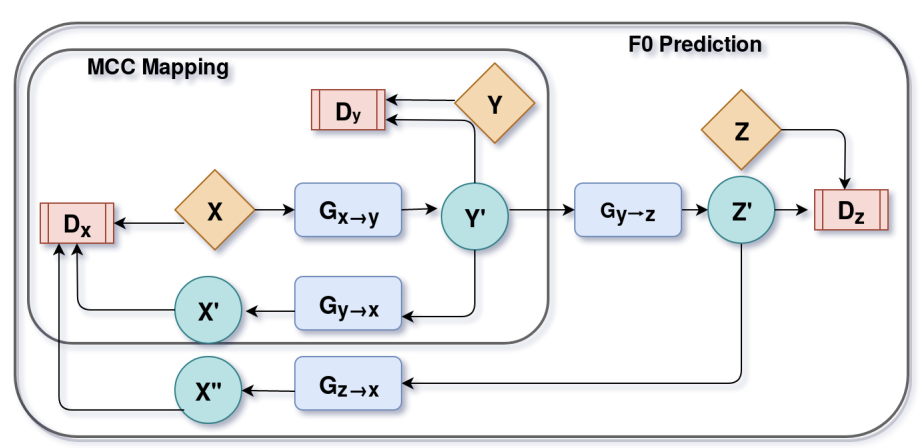 CinC-GAN for Effective F0 prediction for Whisper-to-Normal Speech ConversionMaitreya Patel , Mirali Purohit, Jui Shah, and Hemant A Patil
CinC-GAN for Effective F0 prediction for Whisper-to-Normal Speech ConversionMaitreya Patel , Mirali Purohit, Jui Shah, and Hemant A Patil
In 28th European Signal Processing Conference (EUSIPCO) 2020@inproceedings{patel2020cinc, title = {{CinC-GAN} for Effective F0 prediction for Whisper-to-Normal Speech Conversion}, author = {Patel, Maitreya and Purohit, Mirali and Shah, Jui and Patil, Hemant A}, booktitle = {28th European Signal Processing Conference (EUSIPCO)}, year = {2020}, organization = {IEEE}, }
-
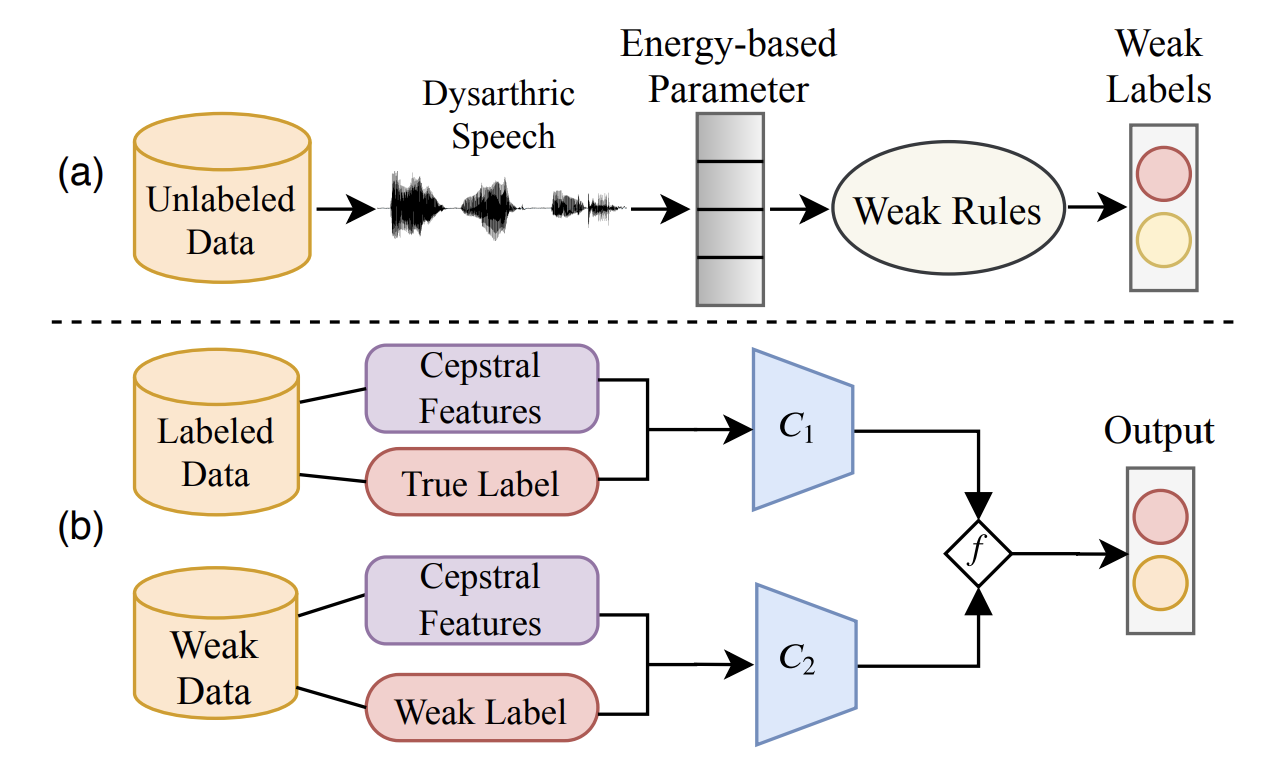 Weak Speech Supervision: A case study of Dysarthria Severity ClassificationMirali Purohit, Mihir Parmar, Maitreya Patel , Harshit Malaviya, and Hemant A Patil
Weak Speech Supervision: A case study of Dysarthria Severity ClassificationMirali Purohit, Mihir Parmar, Maitreya Patel , Harshit Malaviya, and Hemant A Patil
In 28th European Signal Processing Conference (EUSIPCO) 2020@inproceedings{purohit2020weak, title = {Weak Speech Supervision: A case study of Dysarthria Severity Classification}, author = {Purohit, Mirali and Parmar, Mihir and Patel, Maitreya and Malaviya, Harshit and Patil, Hemant A}, booktitle = {28th European Signal Processing Conference (EUSIPCO)}, year = {2020}, organization = {IEEE}, }
2019
-
 Novel adaptive generative adversarial network for voice conversionMaitreya Patel , Mihir Parmar, Savan Doshi, Nirmesh J Shah, and Hemant A Patil
Novel adaptive generative adversarial network for voice conversionMaitreya Patel , Mihir Parmar, Savan Doshi, Nirmesh J Shah, and Hemant A Patil
In 11th Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC) 2019@inproceedings{patel2019novel, title = {Novel adaptive generative adversarial network for voice conversion}, author = {Patel, Maitreya and Parmar, Mihir and Doshi, Savan and Shah, Nirmesh J and Patil, Hemant A}, booktitle = {11th Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC)}, pages = {1273--1281}, year = {2019}, organization = {IEEE}, }
-
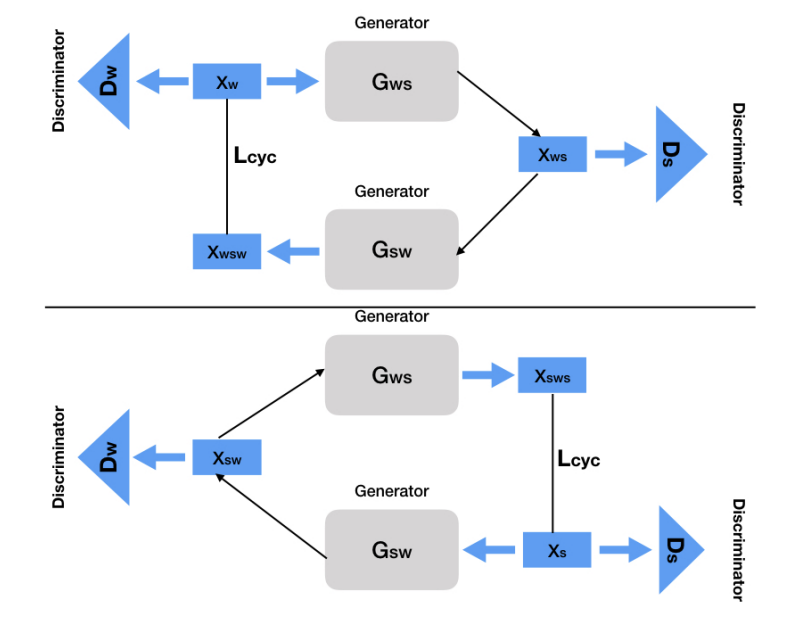 Effectiveness of cross-domain architectures for whisper-to-normal speech conversionMihir Parmar, Savan Doshi, Nirmesh J Shah, Maitreya Patel , and Hemant A Patil
Effectiveness of cross-domain architectures for whisper-to-normal speech conversionMihir Parmar, Savan Doshi, Nirmesh J Shah, Maitreya Patel , and Hemant A Patil
In 27th European Signal Processing Conference (EUSIPCO) 2019@inproceedings{parmar2019effectiveness, title = {Effectiveness of cross-domain architectures for whisper-to-normal speech conversion}, author = {Parmar, Mihir and Doshi, Savan and Shah, Nirmesh J and Patel, Maitreya and Patil, Hemant A}, booktitle = {27th European Signal Processing Conference (EUSIPCO)}, year = {2019}, organization = {IEEE}, }