Maitreya Patel
Research Scientist, Adobe.

I am a Research Scientist at Adobe, working on generative models for visual content creation. Previously, I completed my Ph.D. at Arizona State University, advised by Yezhou Yang and Chitta Baral.
My research is focused on building unified generative models (omni models) — single architectures that natively understand and generate across modalities — and on the large-scale training infrastructure that makes them possible. This spans architecture design for unified tokenization and multimodal generation, pre-training and RL alignment at scale, and inference-time steering for controllability and reliability. I believe true World Models must be generalizable, efficient, controllable, responsible, and grounded in physical laws.
Past Affiliations




News
| Mar 1, 2026 | 🎉 VibeToken accepted at CVPR 2026. |
|---|---|
| Sep 18, 2025 | EraseFlow accepted at NeurIPS’25 as Spotlight. |
| Jul 25, 2025 | 🚀🚀 FlowChef and RefEdit are accepted at ICCV 2025! We’ll also host a tutorial. See you at Hawaii! |
| Jun 5, 2025 | 📝 Released RefEdit - a referring expression based image editing framework. Check out our paper and page! ✨ |
| Jan 22, 2025 | Voilà has been accepted at ICLR’25. |
Selected Publications
-

-

-

-

-

-
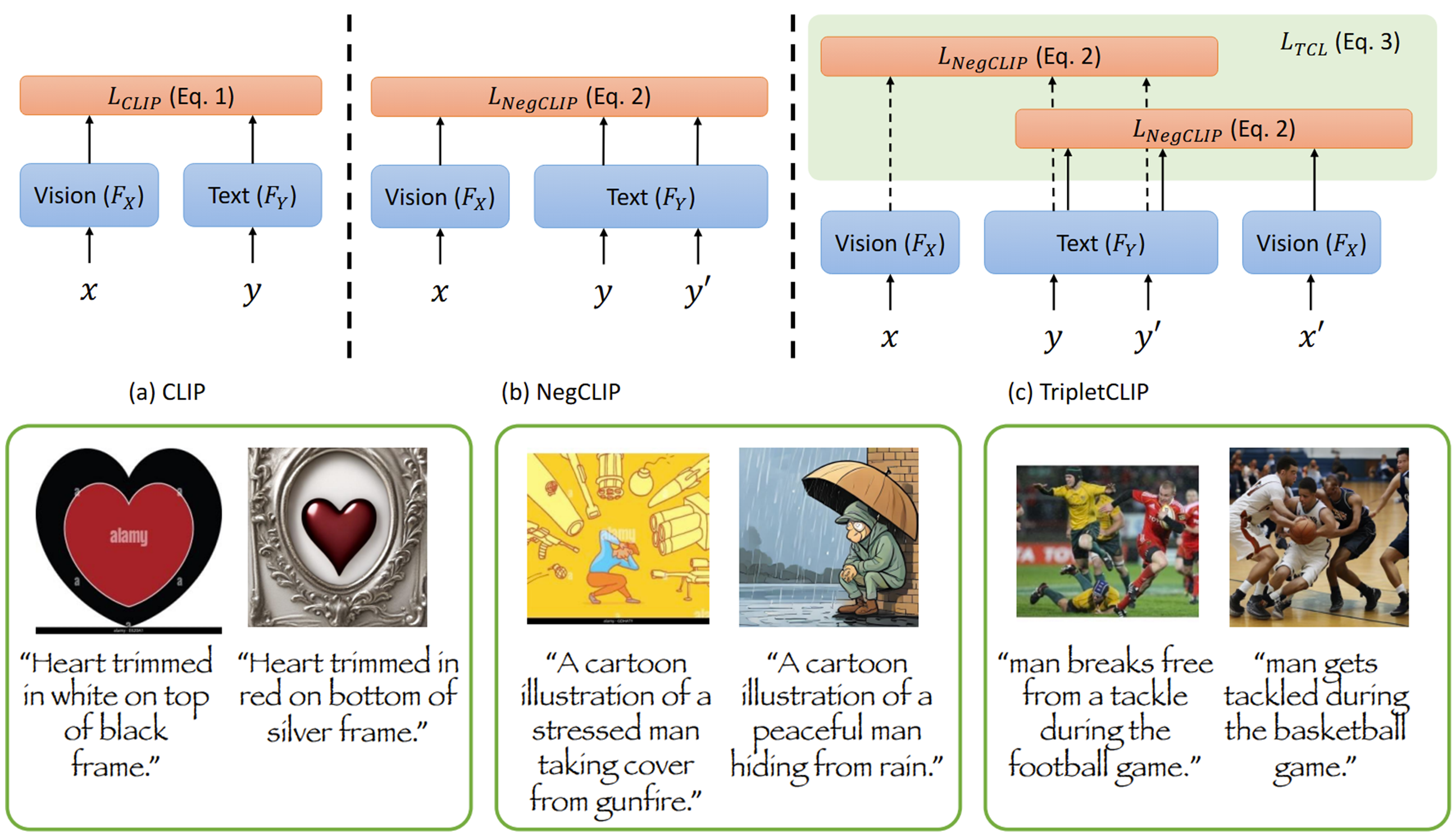
-

-
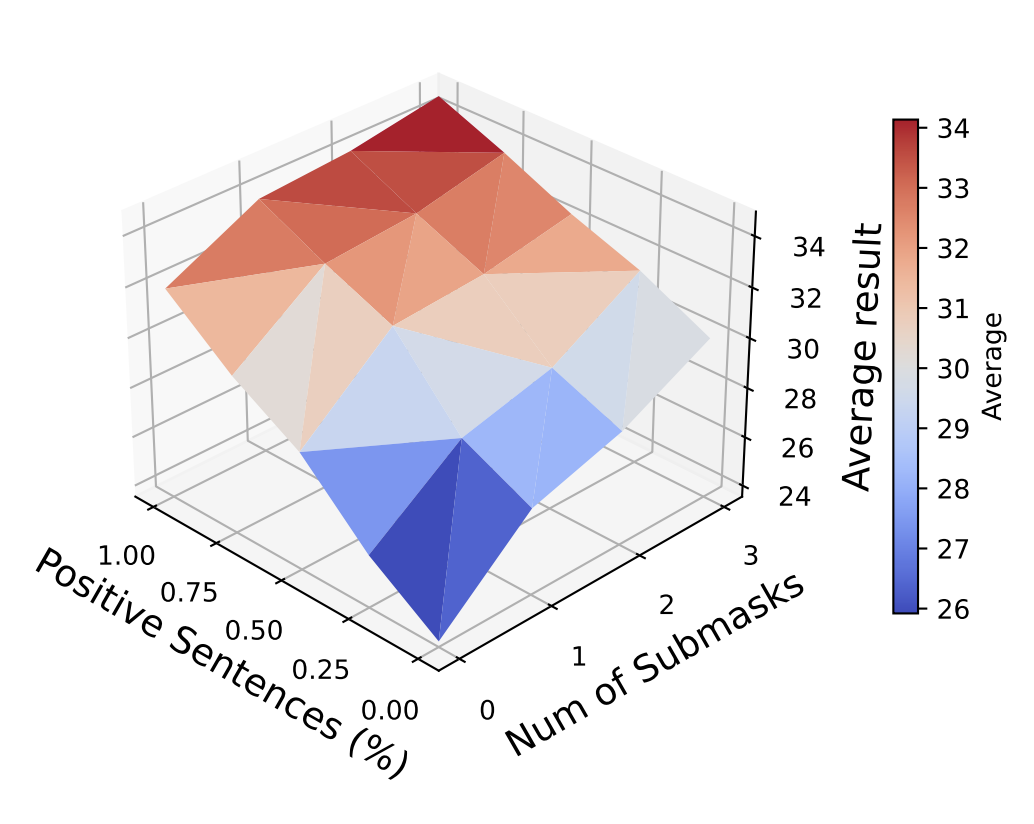
-
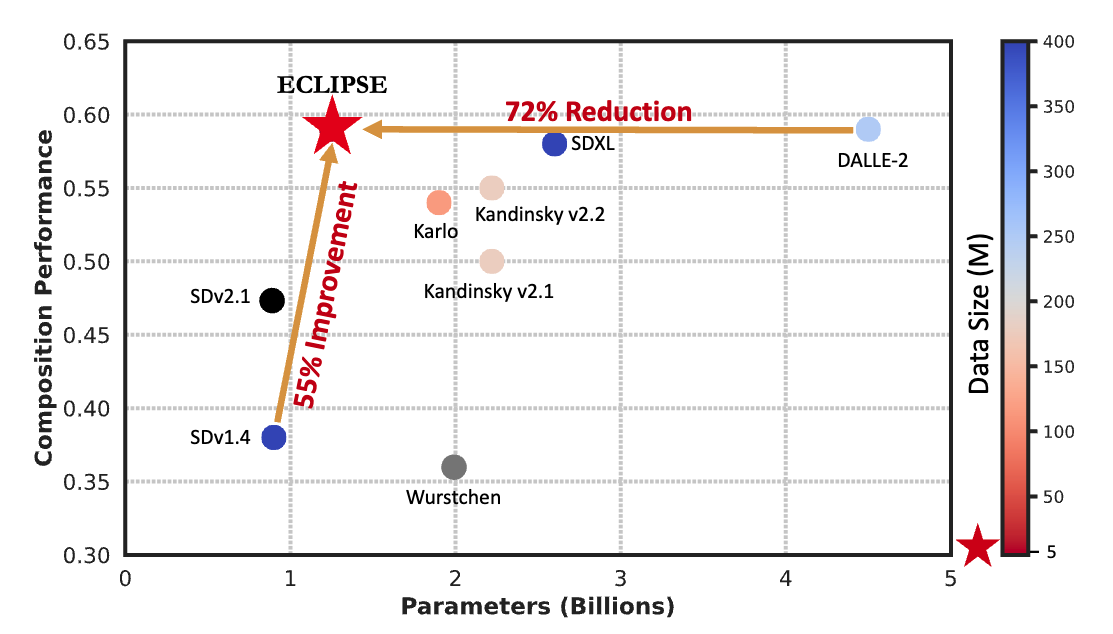 ECLIPSE:A Resource-Efficient Text-to-Image Prior for Image Generations
ECLIPSE:A Resource-Efficient Text-to-Image Prior for Image Generations
In CVPR – 2024
-
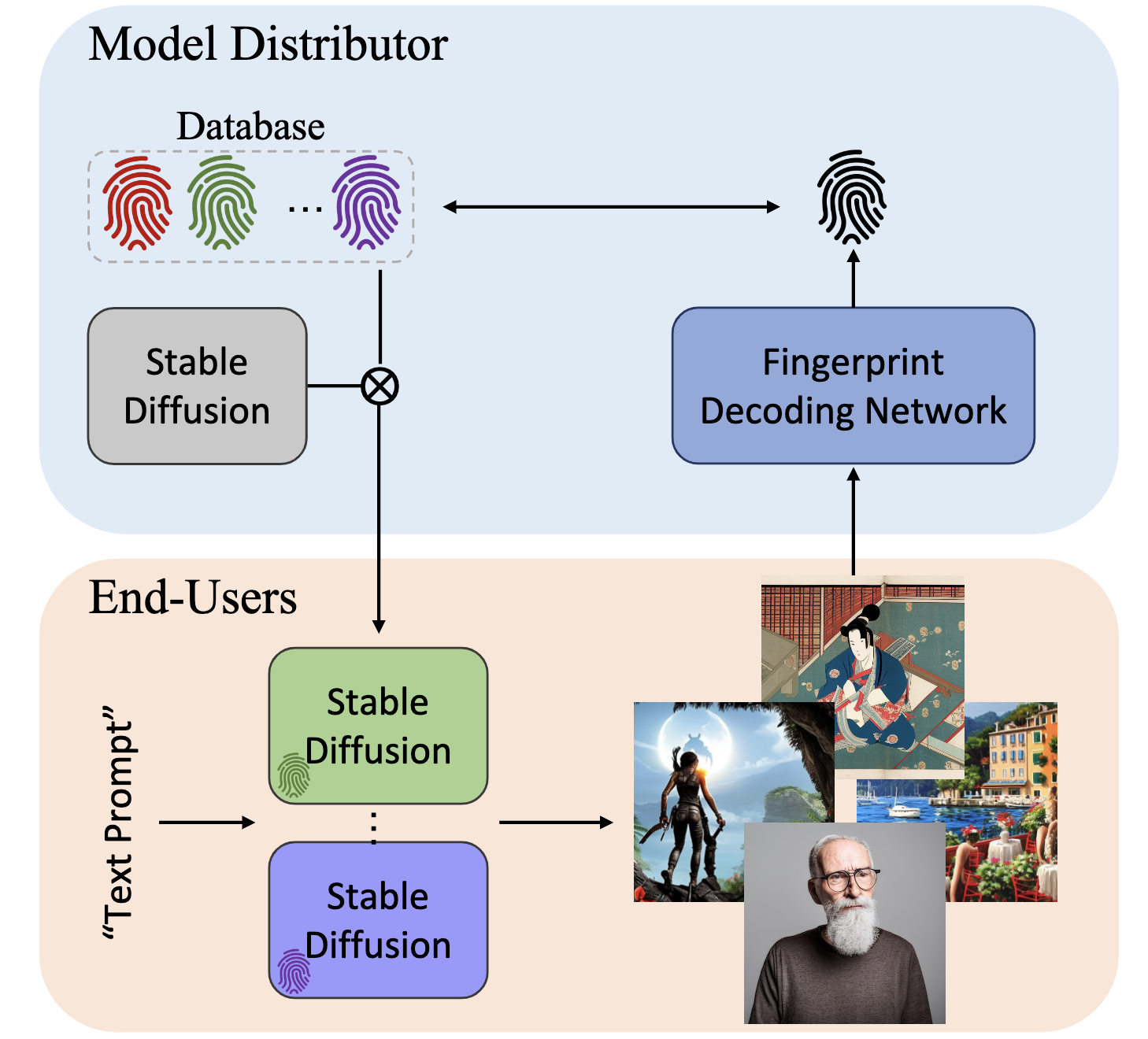
-
-
